Introduction to The World of Data - (OLTP, OLAP, Data Warehouses, Data Lakes and more)
[This article was originally published here]
In this article, I hope to paint a picture of the modern data world and when done you should have a decent understanding of the roles of Data Engineers, Data Analysts and Data Scientists and the technologies that empower them.
The Transactional World (OLTP)
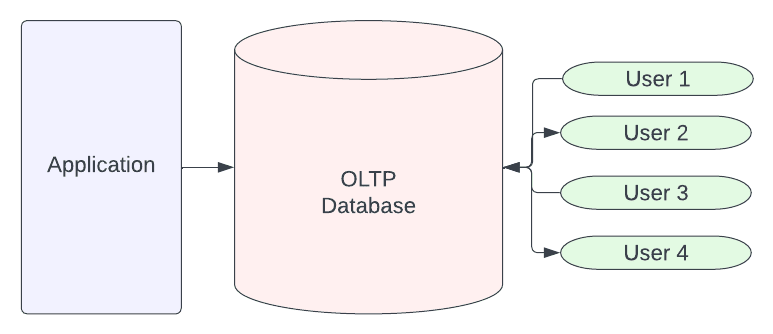
Imagine we are creating the newest social media startup. Our initial focus will be on hiring developers to build our application with languages like Javascript, Python or Ruby and getting it into the hands of potential users. Like any app, data is key as we need users to be registered and log in and for users to be able to add content like photos, blogs and so forth.
Essentially, the data access patterns of applications are often row driven:
- When we create a user, we create a new row
- When we retrieve a user, we get one particular row
- When we delete a user, one row is deleted
This is generally what is called "Transactional Processing", as we are working with data not to analyze it but to facilitate transactions/interactions with our application. The databases we use for our applications like Postgresql, MySQL, MariaDB and others are designed for these kinds of patterns. Systems designed for these kinds of workloads are referred to as OLTP (online transaction processing) systems.
The Need for OLAP
In the early stages, the data in our database may be several hundreds of megabytes or even dozens of gigabytes. We are going to want to use that data to improve our business outcomes so we begin hiring data professionals:
- Data Analysts will begin analyzing our data to create data visualizations and dashboards that help different business units make better decisions.
- Data Scientists will create and train machine learning models to help generate predictions that can be used for making decisions, better-targeted advertising, making useful suggestions and more.
- Data Engineers are responsible for making sure data is available for data consumers and its quality can be trusted.
Eventually, as the size of our data grows especially into the multi-petabyte scale, OLTP systems are going to start to feel slow for analytical queries for several reasons:
- In analytics, you are often not grabbing one row but large subsets of rows
- In analytics, you often only need particular fields/columns, but with row-based data you'll load the entire row data before narrowing it down, then repeat for every row.
- Analytical queries are often more complicated adding logic to transform, aggregate and clean data.
To a point, we can improve the performance of OLTP systems using techniques you can use to optimize any database such as:
- Indexing: Creating a data structure similar to the index in the back of a textbook to more quickly lookup values. (Speeds up Reads, Slows down writes)
- Partitioning: Allow the database to break up the data into subdivisions based on the value of certain fields. For certain queries, the database can now only search those subdivisions. (Not good for fields with lots of possible values/high cardinality)
- Sorting: Sorting the data so that finding data based on the sorted fields can be faster.
- Materialization: Making a physical copy of a subset of the data (can be challenging to keep materialized tables in sync with the original, and consumers need to know to query the materialized table, not the original)
Even then, at the end of the day it may be better to use systems built with analytical queries in mind, referred to as OLAP (Online Analytical Processing) systems which can also benefit from the techniques mentioned above. These have traditionally come in the flavor of specialized systems/platforms called "Data Warehouses", which provide the performance needed but often at very large price tags for storage and use of the platform.
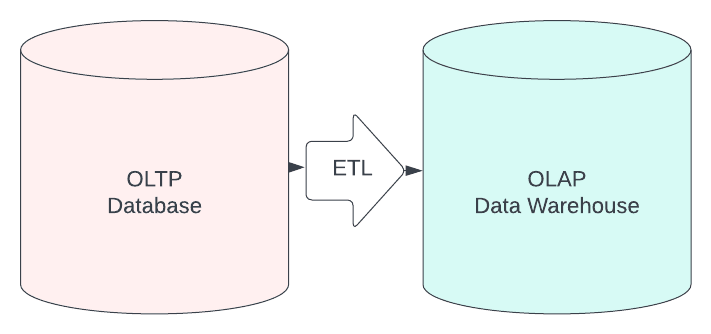
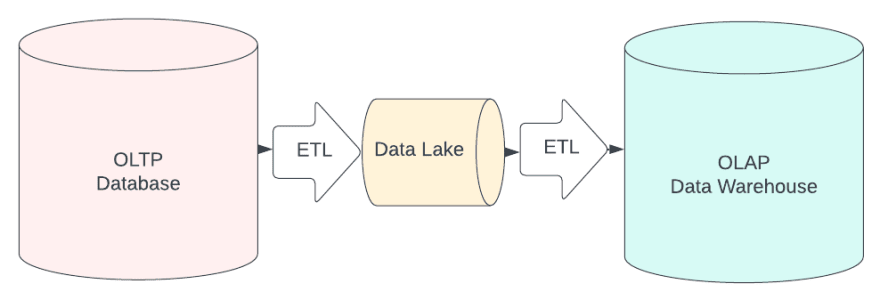
To use a data warehouse, our startup will have to move data currently sitting in our OLTP systems to our OLAP data warehouse using tools and code:
- We will export the data from our OLTP database
- We will run any logic to transform our data to the ideal format for our analytical needs
- We will then load the transformed data into the OLAP data warehouse
This is the role of the Data Engineer to create and maintain these ETL (EXPORT, TRANSFORM, LOAD) workloads so data consumers (Data Analysts and Data Scientists) can make use of reasonably up-to-date data in OLAP systems.
Swimming in a Lake of Data
While now we have the performance needed for large-scale analytics, we run into issues with the costs. It is generally cost-prohibitive to store a copy of ALL our data in the data warehouse, and some data, particularly unstructured data (text-based data like emails, audio/video, sensor data) can't be loaded into the data warehouse.
The solution is to create an intermediary dumping ground for all of our data whether structured or unstructured, and this is known as the data lake.
In the early days, data warehouses and data lakes had to be on-prem (on-premise) so companies would have to buy several large and powerful computers to power the data warehouse which added to the licensing costs of data warehouse software and support. With the creation of the open-source Hadoop framework, businesses could store large amounts of data on a network of cheaper less powerful computers, the data lake. Fast forward to modern times, more and more data warehouse and data lake storage is now cloud-based with the main cloud providers AWS, Azure, and Google Cloud.
So now Data Engineers will ETL the data from OLTP systems into the data lake and then do another ETL for a subset of mission-critical data in the data warehouse.
Data Sprawl & Data Drift
Now it is looking like we have three copies of our data:
- The original data in our OLTP sources
- The copy in our data lake
- The copy in our data warehouse
This is actually only the beginning of the number of copies that will get made that the data engineer needs to track and keep in sync.
The problem comes in that you just can't give all consumers access to all the data to maintain all the security, regulatory and governance responsibilities of the enterprise.
- Some departments probably shouldn't have access to certain datasets
- Some should have access, but not to certain columns (SSN, Private Health Info) or rows (customers that have opted out of information use)
- Some departments need the data to have different column names and other changes that other departments don't need.
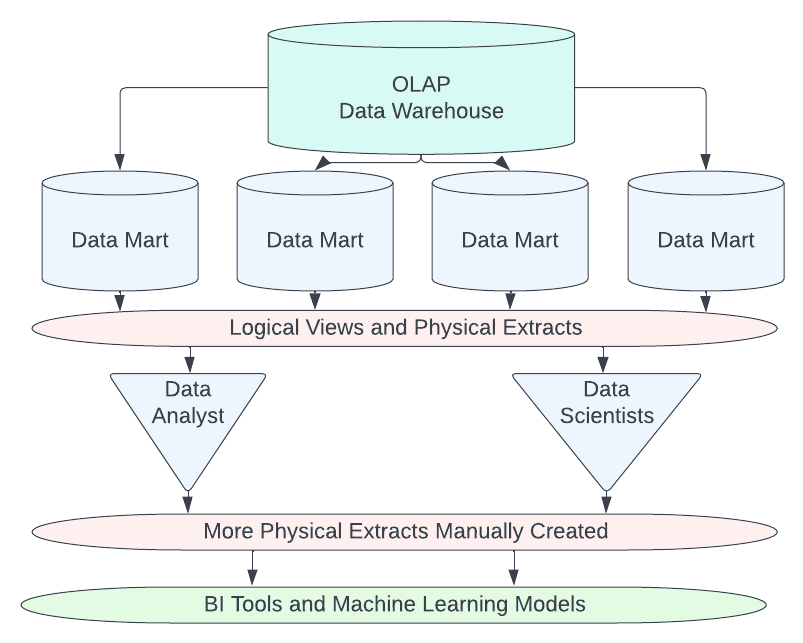
To facilitate this, the data engineer will create data marts which are essentially sub-data warehouses. So for example, for the marketing department we may create a data mart and inside it load some data:
- We may create a "logical view" of customers that don't include credit card numbers or SSNs, this isn't a copy but a pre-filtered view of the existing data accessible from their mart.
- Marketing often likes to run analytics on sales data by month so we may do monthly extract into their data mart, this is actually a physical copy of a subset of the original. (it will be faster to query the subset than to query the full dataset)
This can result in a large network of marts and extracts adding to our storage and platform costs. Although... it gets worse...
A data analyst on the marketing team may be creating a dashboard for the last week of sales data so to improve performance they query the data and export an extract to their computer for faster performance on their favorite BI Dashboard tool (Tableau, Power BI, Hex, Preset). Now we have a copy of the data that the data engineer isn't aware of, can't manage access to and has no idea whether is in sync. This non-accountable copy is being used to create dashboards that critical business decisions are based on. This problem with the growth of data copies is referred to as data drift.
Along with data drift, anytime consumers need a previously hidden column to be visible or other data changes they have to make a request with the data engineer who is constantly working through a backlog of requests, maintaining existing ETL pipelines and creating new ones resulting in simple requests taking weeks or months slowing down the time to business insights.
One may say, just hire more data engineers. Unfortunately, there just aren't enough data engineers to keep up with needs resulting in a multi-billion dollar market for tools to help make this whole process become easier.
The Data Lakehouse Dream
One approach that has been embraced in recent times to simplify all of this is the idea of why not just run more or all of our analytical workloads on the data lake instead of the data warehouse.
- We reduce the cost of storage and the data warehouse
- We reduce data drift, as the data lake becomes the single source of truth
This architecture is referred to as the Data Lakehouse, essentially using the data lake as your data warehouse. In the past, this often did not go well resulting in "data swamps" for several reasons.
- The structure and format of the data wasn't conducive to fast processing at scale (lots of csv and json files)
- It wasn't easy to use
- Processing frameworks weren't fast enough to load and query the data
- It was tricky to track what datasets existed and to control who has access
Luckily, innovation across a lot of high-value open-souce projects have alleviated many of these concerns making Data Lakehouses practical and desirable.
The Components of Data Lakehouse
Storage and Storage Format
- Cloud object storage with cloud providers like AWS, Azure and Google Cloud is super cheap making file storage a trivial cost
- Newer binary columnar file formats such as Apache Parquet make storing data in standard ways optimized for analytics easy
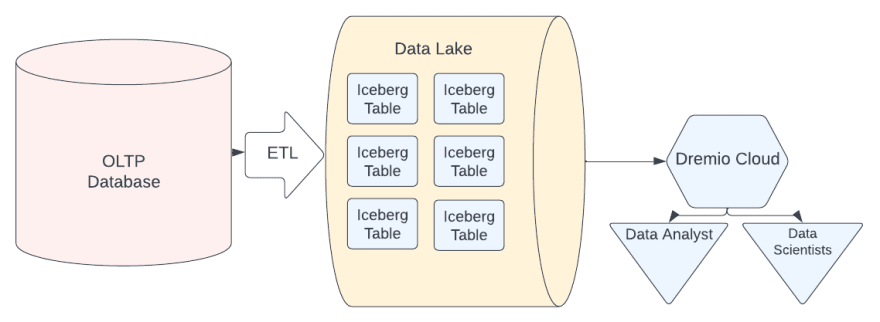
Table Formats
We may have our sales data broken down in our object storage into thousands of parquet files, but when we run analytics we want to recognize those files as one table and this is the role of table formats like Apache Iceberg. Apache Iceberg allows us to group files in our data lake as tables and also maintain metadata that processing tools (query engines) can use to increase their performance when scanning these tables.
Read a Comparison of different table formats
We will also need a catalog to track all of these tables, with the open-source Project Nessie we can do just that, and also get great versioning features similar to using Git when developing applications allowing data engineers to practice "data as code" and "write-audit-publish" patterns on their data.
Video on Dremio's Project Nessie-based Arctic Service
In-Memory Processing and Data Transport
While parquet is a great file format for analytics, if an engine loads the file into a row-based format we end up losing a lot of the benefits. The Apache Arrow project creates an in-memory columnar format, and the Apache Arrow Flight project allows us to move data from system to system in that format eliminating the speed hits from serialization/deserialization when loading files or sending data across the wire. Apache Arrow Gandiva also allows queries to be pre-compiled to native code prior to execution for even more performance gains.
Openness
All these components are open source and allow any engine to incorporate and use them so you avoid two other problems with data warehouses and proprietary formats:
- Vendor lock-in, once your data is in the data warehouse it can be a lot of work to get it back out if you switch providers.
- Tool lock-out, if new data engines and tools are created, since your data is in a proprietary format you can't use them.
The Final Piece of the Puzzle
Hearing about all these components sounds great, but what everyone wants isn't to have to setup and configure all these components but instead to have a platform and tool that brings this all together in an easy-to-use package, and that platform is Dremio. With Dremio you can work with the data directly from your data lake. No copies, easy access, high performance.
With Dremio the data lakehouse comes to life as it addresses all the problems we've explored throughout this article.
Performance on the data lake
More About Dremio's Performance
- Dremio is built top to bottom with Apache Arrow allowing to process queries fast and at scale
- Dremio uses its C3(columnar cloud cache) technology to help speed up queries on cloud object storage and reduce costs.
- With Dremio's reflections, you can create reusable materializations that automatically sync to speed up the process on multiple datasets and queries. It is as easy as flipping a switch. Now you can have sub-second BI dashboards without the need for extracts.
Governance and Collaboration
More on Dremio's Governance and Collaboration
- You make data self-serve using Dremio's semantic layers allowing you to distribute datasets into spaces and folders.
- You can control which users and roles can access each space, folder and dataset for easy and granular governance to maintain regulatory compliance and security.
- Control access to rows and columns using pre-filtered virtual datasets or row/column access policies.
Ease of Use
- Dremio has a really straightforward easy to use UI
- Robust SQL Editor for writing the queries you need
Cost Optimization
- You can auto-scale and granularly control cloud computing power to only pay for what you need reducing your cloud compute costs significantly over other platforms.
- Free tier, no software or licensing costs to get started. Dremio provides powerful data analytics tools available to enterprises of all sizes.
Conclusion
Engineering data to unlock the value it can provide has come a long way as we've tried different ways to analyze larger and larger amounts of data. We are now at a point where this all becomes a bit simpler with data lakehouse architecture which can address the data engineer shortage while also enabling Analysts and Scientists the ability to do their jobs without long waits for data or incurring data drift.
To follow advancements in the data world follow the following twitter accounts: