SQL Query on MinIO

Querying files on Object Storage platform has been possible for a while now - thanks to Trino/Presto, Spark and several others. However, anyone who has used one of these, knows the pain of tuning JVMs, oversized cloud bills, long engineering hours and generally underwhelming experience. Even the native S3 Select API supports a relatively small set of Select commands which may be useful in limited cases.
Full fledged analytical applications, AI, ML workloads, dashboards - need a high performance query engine, that understands standard SQL parlance.
In this post we'll take a look at querying parquet files on MinIO or other S3 compatible systems using DataFusion - the modern query engine written in Rust. Datafusion leverages the in-memory columnar format Apache Arrow.
Setup
MinIO
MinIO offers high-performance, S3 compatible object storage.
Native to Kubernetes, MinIO is the only object storage suite available on
every public cloud, every Kubernetes distribution, the private cloud and the
edge.
I'll use MinIO for demonstration purposes in this blog. Setup a MinIO server instance and upload the Parquet file(s) in a bucket/prefix. If you don't have Parquet files handy you could uses the files from here.
To deploy a single node test MinIO server on Linux:
wget https://dl.min.io/server/minio/release/linux-amd64/minio
chmod +x minio
./minio server /dataTo upload Parquet file(s):
wget https://dl.min.io/client/mc/release/linux-amd64/mc
chmod +x mc
./mc alias set minio http://127.0.0.1 minioadmin minioadmin
./mc mb minio/testbucket
wget https://ursa-labs-taxi-data.s3.us-east-2.amazonaws.com/2009/01/data.parquet
./mc cp data.parquet minio/testbucketNow, we're ready to deploy DataFusion to query the parquet files.
DataFusion
DataFusion is a query execution framework, written in Rust. It uses Apache Arrow as its in-memory format. From their docs:
DataFusion supports both an SQL and a DataFrame API for building logical query plans as well as a query optimizer and execution engine capable of parallel execution against partitioned data sources (CSV and Parquet) using threads.
DataFusion can read Parquet and CSV files from the underlying filesystem by default. Rest of the data read integrations are available via simple plugins for the users. This means, to query files directly from S3 / compatible stores, we'll need to use the ObjectStore-S3 plugin from the DataFusion ecosystem.
In simpler terms, DataFusion is a Rust Crate aka library. To use DataFusion, we'll need to write a Rust program and import DataFusion there.
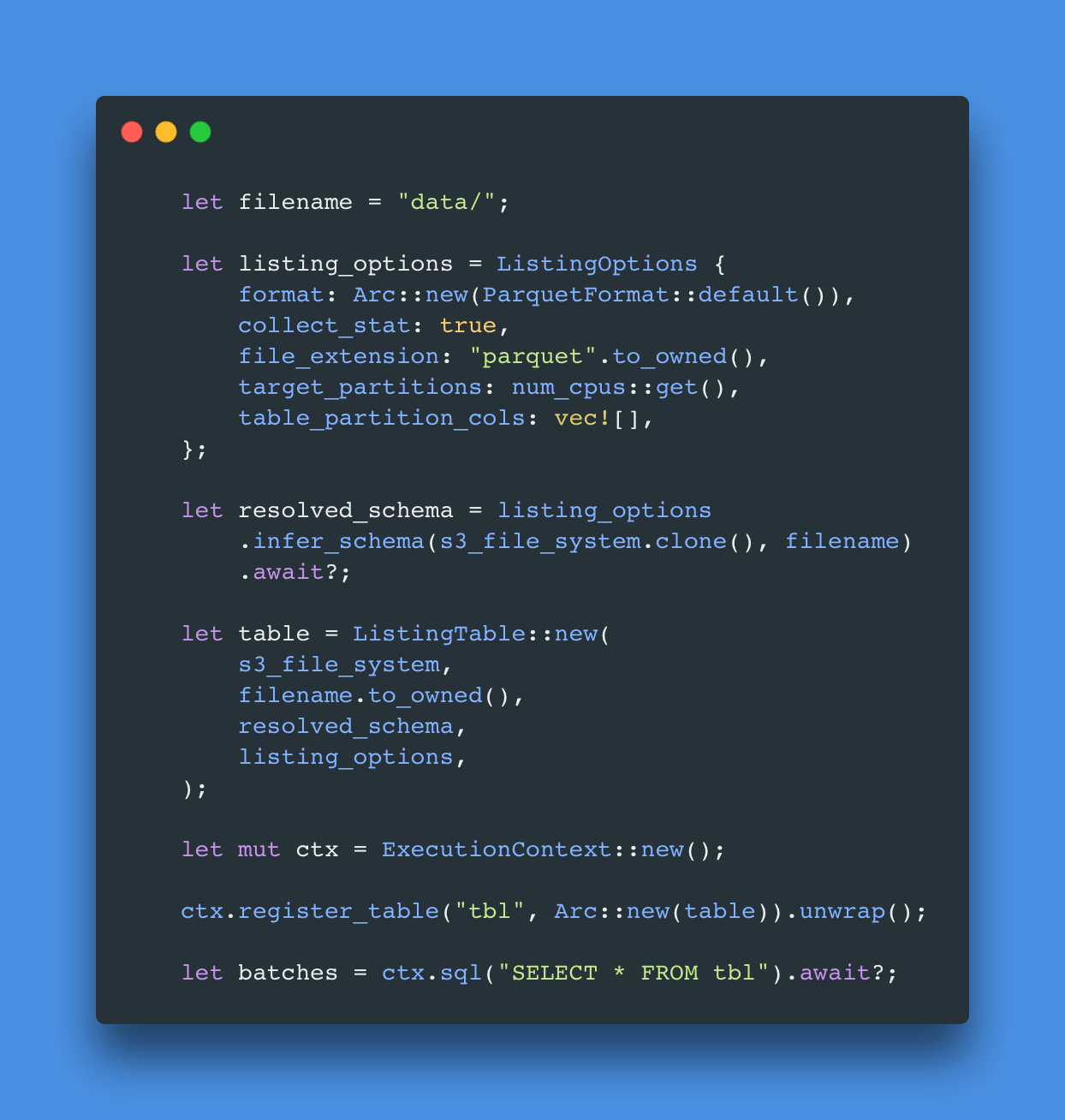
Sample Code
Now that you have a high level idea if the overall approach, let's dive right in to the code. To start with, install rust on the machine where you intend to run this. Then download the code from the repo here: https://github.com/nitisht/datafusion-s3
git clone git@github.com:nitisht/datafusion-s3.gitOpen the file main.rs. This file has the plugin code (ObjectStore-S3 plugin) that allows Datafusion to connect/read data from S3 compatible systems e.g. MinIO. You can skip to the main function in this file to look at the S3 client part of the code. Here we essentially create a S3 filesystem that is the input for listing table created in DataFusion. Finally we register the table created previously and execute the query on this table.
Before running the code, you'll need MinIO up and running. Make sure to change the file path (bucket/prefix), credentials and MinIO endpoint URL, per actual values. Finally, run the code using cargo run. You should see an output like this if you're running the data.parquet used above.

Summary
In this article we took a look at a hands on approach to query and analyse ad hoc parquet files stored on an Object Storage system like MinIO using DataFusion project from Apache Arrow ecosystem.